Contact Maps¶
The contact_map package includes some tricks to study contact maps
in protein dynamics, based on tools in MDTraj. This notebook shows
examples and serves as documentation.
As an example, we’ll use part of a trajectory of the KRas protein bound
to GTP, which was provided by Sander Roet. KRas is a protein that plays
a role in many cancers. For simplicity, the waters were removed from the
trajectory (although ions are still included). To run this notebook,
download the example files from
https://figshare.com/s/453b1b215cf2f9270769 (total download size about
1.2 MB). Download all files, and extract in the same directory that you
started Jupyer from (so that you have a directory called 5550217 in
your current working directory).
In [1]:
%matplotlib inline
import matplotlib.pyplot as plt
import mdtraj as md
traj = md.load("5550217/kras.xtc", top="5550217/kras.pdb")
topology = traj.topology
In [2]:
from contact_map import ContactMap, ContactFrequency, ContactDifference
Look at a single frame: ContactMap¶
First we make the contact map for the 0th frame. For default parameters (and how to change them) see section “Changing the defaults” below.
In [3]:
%%time
frame_contacts = ContactMap(traj[0])
CPU times: user 137 ms, sys: 6.93 ms, total: 144 ms
Wall time: 145 ms
The built-in plotter requires one of the matplotlib color
maps the set the color
scheme. If you select a divergent color map (useful if you want to look
at contact differences), then you should give the parameters
vmin=-1, and vmax=1. Otherwise, you should use vmin=0 and
vmax=1.
In [4]:
%%time
(fig, ax) = frame_contacts.residue_contacts.plot(cmap='seismic', vmin=-1, vmax=1)
plt.xlabel("Residue")
plt.ylabel("Residue")
CPU times: user 1.09 s, sys: 34.6 ms, total: 1.13 s
Wall time: 1.15 s

The plotting function return the matplotlib Figure and Axes
objects, which allow you to make more manipulations to them later. I’ll
show an example of that in the “Changing the defaults” section.
We can also plot the atom-atom contacts, although it takes a little time. The built-in plotting function is best if there are not many contacts (if the matrix is sparse). If there are lots of contacts, sometimes other approaches can plot more quickly. See an example in the “Changing the defaults” section.
In [5]:
%%time
frame_contacts.atom_contacts.plot(cmap='seismic', vmin=-1, vmax=1);
CPU times: user 5.46 s, sys: 102 ms, total: 5.56 s
Wall time: 5.6 s
Out[5]:
(<matplotlib.figure.Figure at 0x107e40150>,
<matplotlib.axes._subplots.AxesSubplot at 0x107def150>)
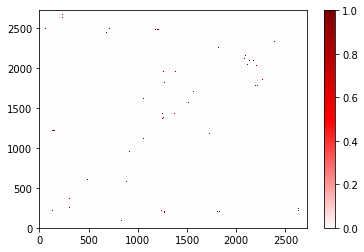
You’ll notice that you don’t see many points here. That is because the
points are typically smaller than a single pixel at this resolution. To
fix that, increase the figure’s size or dpi. (Future updates to
contact_map may provide an option to require that each point be at
least one pixel in size)
Look at a trajectory: ContactFrequency¶
ContactFrequency finds the fraction of frames where each contact
exists.
In [6]:
%%time
trajectory_contacts = ContactFrequency(traj)
CPU times: user 6.02 s, sys: 28 ms, total: 6.05 s
Wall time: 6.08 s
In [7]:
# if you want to save this for later analysis
trajectory_contacts.save_to_file("traj_contacts.p")
# then load with ContactFrequency.from_file("traj_contacts.p")
In [8]:
%%time
fig, ax = trajectory_contacts.residue_contacts.plot(cmap='seismic', vmin=-1, vmax=1);
CPU times: user 3.25 s, sys: 43.1 ms, total: 3.3 s
Wall time: 3.32 s

Compare two: ContactDifference¶
If you want to compare two frequencies, you can use the
ContactDifference class (or the shortcut for it, which is to
subtract a contact frequency/map from another.)
The example below will compare the trajectory to its first frame.
In [9]:
%%time
diff = trajectory_contacts - frame_contacts
CPU times: user 14.2 ms, sys: 4.48 ms, total: 18.7 ms
Wall time: 14.8 ms
A contact that appears in trajectory, but not in the frame, will be at +1 and will be shown in red below. A contact that appears in the frame, but not the trajectory, will be at -1 and will be shown in blue below. The values are the difference in the frequencies (of course, for a single frame, the frequency is always 0 or 1).
In [10]:
%%time
diff.residue_contacts.plot(cmap='seismic', vmin=-1, vmax=1);
CPU times: user 3.3 s, sys: 49.9 ms, total: 3.35 s
Wall time: 3.36 s
Out[10]:
(<matplotlib.figure.Figure at 0x10b0ec990>,
<matplotlib.axes._subplots.AxesSubplot at 0x10bdcab50>)
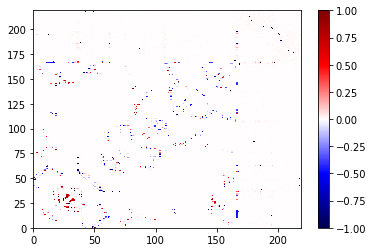
You could have created the same object with:
diff = ContactDifference(trajectory_contact, frame_contacts)
but the simple notation using - is much more straightforward.
However, note that ContactDifference makes a difference between the
frequencies in the two objects, not the absolute count. Otherwise the
trajectory would swamp the single frame, and there would be no blue in
that picture!
List the residue contacts that show the most difference¶
First we look at the contacts that are much more important in the trajectory than the frame. Then we look at the contacts that are more important in the frame than the trajectory.
The .most_common() method gives a list of the contact pairs and the
frequency, sorted by frequency. See also
collections.Counter.most_common() in the standard Python
collections module.
Here we do this with the ContactDifference we created, although it
works the same for ContactFrequency and ContactMap (with the
single-frame contact map, the ordering is a bit nonsensical, since every
entry is either 0 or 1).
In [11]:
%%time
# residue contact more important in trajectory than in frame (near +1)
diff.residue_contacts.most_common()[:10]
CPU times: user 7.53 ms, sys: 1.97 ms, total: 9.5 ms
Wall time: 8.1 ms
Out[11]:
[([ALA146, GLN22], 0.9900990099009901),
([PHE82, PHE141], 0.9801980198019802),
([ALA83, LYS117], 0.9702970297029703),
([ILE84, GLU143], 0.9702970297029703),
([PHE90, ALA130], 0.9702970297029703),
([ALA146, ASN116], 0.9702970297029703),
([ALA155, VAL152], 0.9504950495049505),
([LEU113, ILE139], 0.9504950495049505),
([LEU19, LEU79], 0.9405940594059405),
([VAL81, ILE93], 0.9405940594059405)]
In [12]:
# residue contact more important in frame than in trajectory (near -1)
list(reversed(diff.residue_contacts.most_common()))[:10]
# alternate: diff.residue_contacts.most_common()[:-10:-1] # (thanks Sander!)
Out[12]:
[([NA6828, THR87], -0.9900990099009901),
([CL6849, NA6842], -0.9900990099009901),
([NA6834, SER39], -0.9900990099009901),
([PRO34, ASP38], -0.9900990099009901),
([ALA59, GLU37], -0.9900990099009901),
([GLN25, ASP30], -0.9900990099009901),
([NA6842, GLY13], -0.9900990099009901),
([CL6865, GLN43], -0.9900990099009901),
([TYR40, TYR32], -0.9900990099009901),
([SER65, GLU37], -0.9900990099009901)]
List the atoms contacts most common within a given residue contact¶
First let’s select a few residues from the topology. Note that GTP has residue ID 201 in the PDB sequence, even though it is only residue 166 (counting from 0) in the topology. This is because some of the protein was removed, and therefore the PDB is missing those residues. The topology only counts the residues that are actually present.
In [13]:
val81 = topology.residue(80)
asn116 = topology.residue(115)
gtp201 = topology.residue(166)
print val81, asn116, gtp201
VAL81 ASN116 GTP201
We extended the standard .most_common() to take an optional
argument. When the argument is given, it will filter the output to only
include the ones where that argument is part of the contact. For
example, the following gives the residues most commonly in contact with
GTP.
In [14]:
for contact in trajectory_contacts.residue_contacts.most_common(gtp201):
if contact[1] > 0.1:
print contact
([GTP201, LEU120], 0.6435643564356436)
([GTP201, ASP119], 0.6237623762376238)
([LYS147, GTP201], 0.6138613861386139)
([ALA146, GTP201], 0.594059405940594)
([SER145, GTP201], 0.594059405940594)
([LYS117, GTP201], 0.594059405940594)
([ASP33, GTP201], 0.5742574257425742)
([GLY12, GTP201], 0.5643564356435643)
([GLY13, GTP201], 0.5544554455445545)
([VAL14, GTP201], 0.5346534653465347)
([ALA11, GTP201], 0.5346534653465347)
([GTP201, GLY15], 0.5247524752475248)
([GTP201, LYS16], 0.5247524752475248)
([SER17, GTP201], 0.5247524752475248)
([ALA18, GTP201], 0.5247524752475248)
([ASN116, GTP201], 0.4752475247524752)
([ASP57, GTP201], 0.40594059405940597)
([GTP201, GLU63], 0.39603960396039606)
([GLU37, GTP201], 0.3465346534653465)
([VAL29, GTP201], 0.297029702970297)
([NA6833, GTP201], 0.2079207920792079)
([NA6843, GTP201], 0.18811881188118812)
([THR35, GTP201], 0.1485148514851485)
([PRO34, GTP201], 0.1485148514851485)
([NA6829, GTP201], 0.1485148514851485)
We can also find all the atoms, for all residue contacts, that are in contact with a given residue, and return that sorted by frequency.
In [15]:
diff.most_common_atoms_for_residue(gtp201)[:15]
Out[15]:
[([GTP201-C6, LYS117-CB], 0.5346534653465347),
([LYS117-CA, GTP201-O6], 0.5247524752475248),
([GTP201-C6, LYS117-CA], 0.5247524752475248),
([GTP201-C8, GLY15-CA], 0.5148514851485149),
([GTP201-N7, GLY15-CA], 0.5148514851485149),
([GTP201-O2', ASP33-CG], 0.5148514851485149),
([GLY13-C, GTP201-PB], 0.49504950495049505),
([LYS117-N, GTP201-O6], 0.49504950495049505),
([GTP201-C2, LYS147-CB], 0.49504950495049505),
([GTP201-O3A, GLY13-C], 0.48514851485148514),
([GTP201-O2', ASP33-OD2], 0.48514851485148514),
([ASN116-OD1, GTP201-O6], 0.4752475247524752),
([ASN116-CG, GTP201-O6], 0.45544554455445546),
([GTP201-O6, LYS117-CB], 0.45544554455445546),
([GTP201-N7, ASN116-ND2], 0.45544554455445546)]
Finally, we can look at which atoms are most commonly in contact within a given residue contact pair.
In [16]:
trajectory_contacts.most_common_atoms_for_contact([val81, asn116])
Out[16]:
[([ASN116-CB, VAL81-CG1], 0.9702970297029703),
([ASN116-CG, VAL81-CG1], 0.24752475247524752),
([VAL81-CG1, ASN116-ND2], 0.21782178217821782),
([VAL81-CG1, ASN116-N], 0.0594059405940594)]
Changing the defaults¶
This sections covers several options that you can modify to make the contact maps faster, and to focus on what you’re most interested in.
The first three options change which atoms are included as possible
contacts. We call these query and haystack, and although they
are conceptually equivalent, the algorithm is designed such that the
query should have fewer atoms than the haystack.
Both of these options take a list of atom index numbers. These are most easily created using MDTraj’s atom selection language.
In [17]:
# the default selection is
default_selection = topology.select("not water and symbol != 'H'")
print len(default_selection)
1408
Using a different query¶
In [18]:
switch1 = topology.select("resSeq 32 to 38 and symbol != 'H'")
switch2 = topology.select("resSeq 59 to 67 and symbol != 'H'")
gtp = topology.select("resname GTP and symbol != 'H'")
mg = topology.select("element Mg")
cations = topology.select("resname NA or resname MG")
sodium = topology.select("resname NA")
In [19]:
%%time
sw1_contacts = ContactFrequency(trajectory=traj, query=switch1)
CPU times: user 2.29 s, sys: 17.7 ms, total: 2.31 s
Wall time: 2.32 s
In [20]:
sw1_contacts.residue_contacts.plot(cmap='seismic', vmin=-1, vmax=1)
Out[20]:
(<matplotlib.figure.Figure at 0x10d098a50>,
<matplotlib.axes._subplots.AxesSubplot at 0x107c20590>)
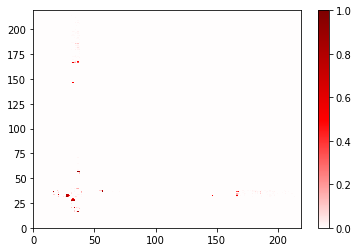
Using a different haystack¶
Currently, changing the haystack has essentially no effect on the performance. However, I expect to change that in the future (requires making some modifications to MDTraj).
In [21]:
%%time
cations_switch1 = ContactFrequency(trajectory=traj, query=cations, haystack=switch1)
CPU times: user 2.11 s, sys: 9.41 ms, total: 2.12 s
Wall time: 2.13 s
In [22]:
(fig, ax) = cations_switch1.residue_contacts.plot(cmap='seismic', vmin=-1, vmax=1)

Let’s zoom in on that. To do this, we’ll do a little MDTraj magic so
that we can change the atom ID numbers, which are what go into our
cations and switch1 objects, into residue ID numbers (and
we’ll use Python sets to remove repeats):
In [23]:
def residue_for_atoms(atom_list, topology):
return set([topology.atom(a).residue.index for a in atom_list])
In [24]:
switch1_residues = residue_for_atoms(switch1, traj.topology)
cation_residues = residue_for_atoms(cations, traj.topology)
Now we’ll plot again, but we’ll change the x and y axes so that
we only see switch 1 along x and cations along y:
In [25]:
(fig, ax) = cations_switch1.residue_contacts.plot(cmap='seismic', vmin=-1, vmax=1)
ax.set_xlim(min(switch1_residues), max(switch1_residues) + 1)
ax.set_ylim(min(cation_residues), max(cation_residues) + 1)
Out[25]:
(167, 198)

Here, of course, the boxes are much larger, and are long rectangles instead of squares. The box represents the residue number that is to its left and under it. So the most significant contacts here are between residue 36 and the ion listed as residue 167. Let’s see just how frequently that contact is made:
In [26]:
print cations_switch1.residue_contacts.counter[frozenset([36, 167])]
0.485148514851
So about half the time. Now, which residue/ion are these? Remember, these indices start at 0, even though the tradition in science (and the PDB) is to count from 1. Furthermore, the PDB residue numbers for the ions skip the section of the protein that has been removed. But we can easily obtain the relevant residues:
In [27]:
print traj.topology.residue(36)
print traj.topology.residue(167)
GLU37
MG202
So this is a contact between the Glu37 and the magnesium ion (which is listed as residue 202 in the PDB).
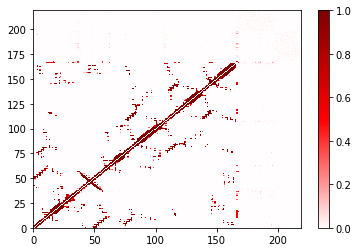
Changing how many neighboring residues are ignored¶
By default, we ignore atoms from 2 residues on either side of the given
residue (and in the same chain). This is easily changed. However,
even when you say to ignore no neighbors, you still ignore the residue’s
interactions with itself.
Note: for non-protein contacts, the chain is often poorly defined.
In this example, the GTP and the Mg are listed sequentially in residue
order, and therefore they are considered “neighbors” and their contacts
are ignored.
In [28]:
%%time
ignore_none = ContactFrequency(trajectory=traj, n_neighbors_ignored=0)
CPU times: user 9.58 s, sys: 82.9 ms, total: 9.66 s
Wall time: 9.77 s
In [29]:
ignore_none.residue_contacts.plot(cmap='seismic', vmin=-1, vmax=1);
Using a different cutoff¶
The size of the cutoff has a large effect on the performance. The default is (currently) 0.45nm.
In [30]:
%%time
large_cutoff = ContactFrequency(trajectory=traj, cutoff=1.5)
CPU times: user 3min 41s, sys: 2.95 s, total: 3min 44s
Wall time: 3min 47s
The cost of the built-in plot function also depends strongly on the number of contacts that are made. It is designed to work well for sparse matrices; as the matrix gets less sparse, other approaches may be better. Here’s an example:
In [31]:
%%time
large_cutoff.residue_contacts.plot(cmap='seismic', vmin=-1, vmax=1);
CPU times: user 35.7 s, sys: 1.51 s, total: 37.2 s
Wall time: 37.6 s
Out[31]:
(<matplotlib.figure.Figure at 0x111f5fd10>,
<matplotlib.axes._subplots.AxesSubplot at 0x11206e990>)
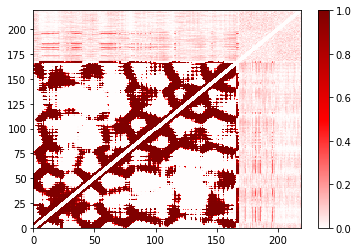
In [32]:
%%time
import matplotlib
cmap = matplotlib.pyplot.get_cmap('seismic')
norm = matplotlib.colors.Normalize(vmin=-1, vmax=1)
plot = matplotlib.pyplot.pcolor(large_cutoff.residue_contacts.df, cmap='seismic', vmin=-1, vmax=1)
plot.cmap.set_under(cmap(norm(0)));
CPU times: user 1.5 s, sys: 35.9 ms, total: 1.54 s
Wall time: 1.54 s

In this case, using the pandas.DataFrame representation (obtained
using .df) is faster. On the other hand, try using this approach on
the atom-atom picture at the top! That will take a while.
You’ll notice that these may not be pixel-perfect copies. This is
because the number of pixels doesn’t evenly divide into the number of
residues. You can improve this by increasing the resolution (dpi in
matplotlib) or the figure size. However, in both versions you can see
the overall structure quite clearly. In addition, the color bar is only
shown in the built-in version.